- Overview
- Key Features
- Benefits for Platform Integration
- Next Steps
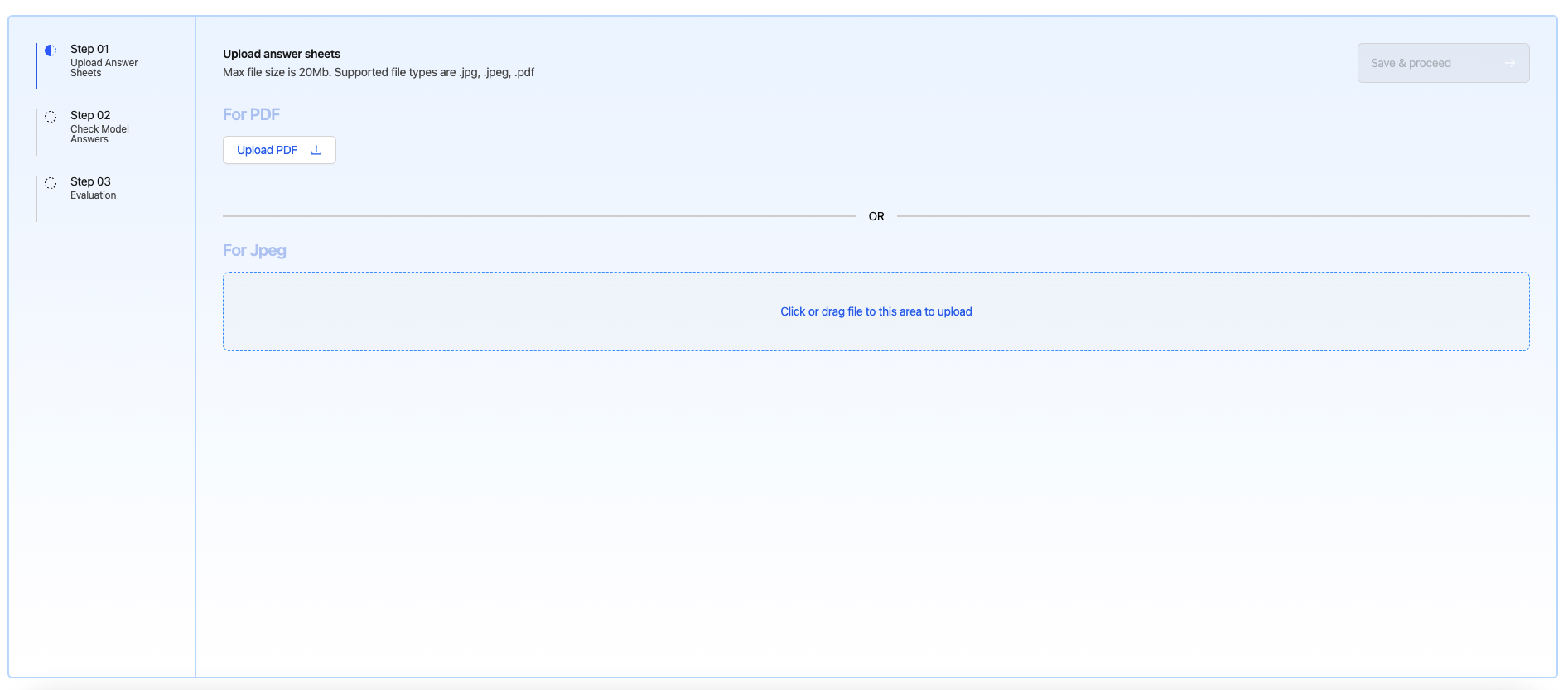
- Upload handwritten answer sheets (as PDFs or JPEGs).
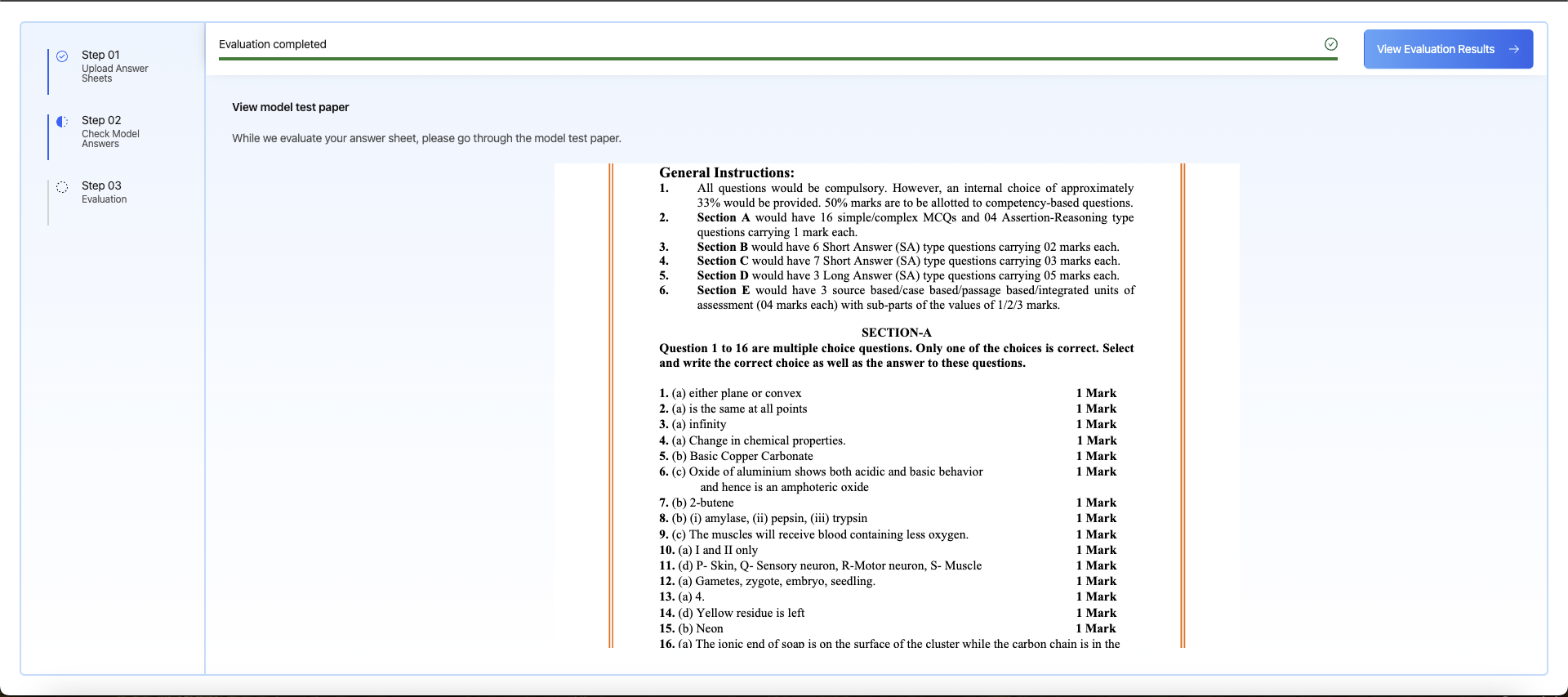
- View model answers for comparison.
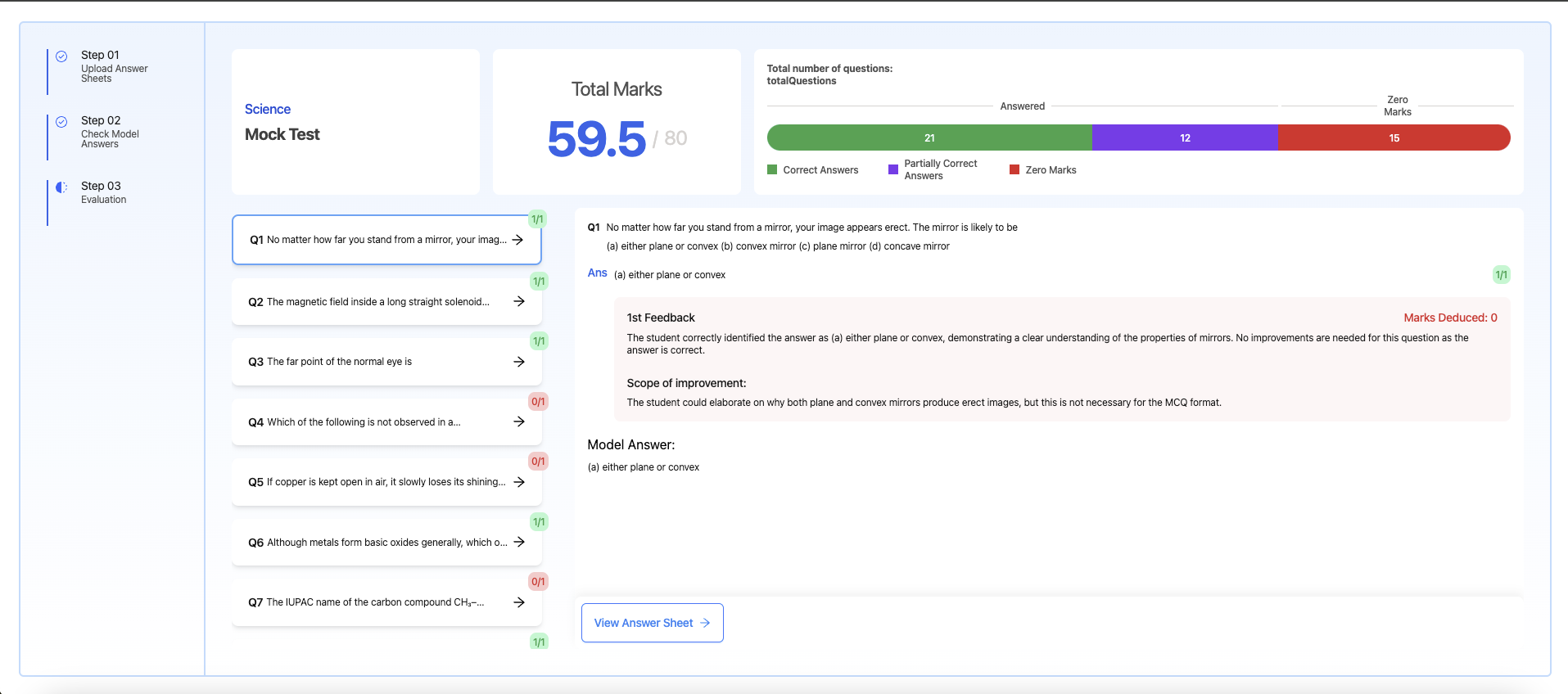
- Receive detailed evaluations with marks, feedback, and suggestions for improvement.
FAQ
How do we integrate the Evaluation Layer Embeddable UI—iframe vs secure link—and how is access controlled?
How do we integrate the Evaluation Layer Embeddable UI—iframe vs secure link—and how is access controlled?
What multimodal inputs does the embeddable UI accept for subjective evaluation?
What multimodal inputs does the embeddable UI accept for subjective evaluation?
Does the embeddable UI support standardized IELTS/TOEFL evaluation flows out of the box?
Does the embeddable UI support standardized IELTS/TOEFL evaluation flows out of the box?
What results can we retrieve after an embeddable evaluation session?
What results can we retrieve after an embeddable evaluation session?
How are human‑in‑the‑loop review, approvals, and rechecks handled in the embeddable flow?
How are human‑in‑the‑loop review, approvals, and rechecks handled in the embeddable flow?
Can we brand the embeddable experience to match our product’s look and feel?
Can we brand the embeddable experience to match our product’s look and feel?
Is the embeddable evaluation flow aligned with CBSE/ICSE curricula and GDPR requirements?
Is the embeddable evaluation flow aligned with CBSE/ICSE curricula and GDPR requirements?
What accuracy should we expect from embeddable evaluations, and how do rubrics/model answers affect it?
What accuracy should we expect from embeddable evaluations, and how do rubrics/model answers affect it?
Can we start with the embeddable UI and then extend into REST/JSON APIs as we scale?
Can we start with the embeddable UI and then extend into REST/JSON APIs as we scale?
What artifacts and analytics are produced from the embeddable evaluation flow?
What artifacts and analytics are produced from the embeddable evaluation flow?